RPC 简介
引言
一直比较关注斗鱼,
之前曾写过一篇斗鱼已公开的运维技术和架构分析。
最近新看到一篇“斗鱼直播平台后端 RPC 架构浅析”。RPC 应该属于 SOA 层。
关于 RPC 相关概念和框架,没有怎么接触过,现在重新了解下。
RPC 简介
RPC 是指远程过程调用,也就是说两台服务器 A/B,一个应用部署在 A 服务器上,想要调用 B 服务器上应用提供的函数/方法, 由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。 比如说,一个方法可能是这样定义的: Employee getEmployeeByName(String fullName) 1. 首先,要解决通讯的问题,主要是通过在客户端和服务器之间建立 TCP 连接,远程过程调用的所有交换的数据都在这个连接里传输。 连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。 2. 要解决寻址的问题,也就是说,A 服务器上的应用怎么告诉底层的 RPC 框架, 如何连接到 B 服务器(如主机或 IP 地址)以及特定的端口, 方法的名称名称是什么,这样才能完成调用。比如基于 Web 服务协议栈的 RPC, 就要提供一个 endpoint URI,或者是从 UDDI 服务上查找。 如果是 RMI 调用的话,还需要一个 RMI Registry 来注册服务的地址。 3. 当 A 服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如 TCP 传递到 B 服务器, 由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(Serialize)或编组(marshal), 通过寻址和传输将序列化的二进制发送给 B 服务器。 4. B 服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式, 然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。 5. 返回值还要发送回服务器 A 上的应用,也要经过序列化的方式发送, 服务器 A 接到后,再反序列化,恢复为内存中的表达方式,交给 A 服务器上的应用。 为什么需要 RPC 呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求, 比如不同的系统间的通讯,甚至不同的组织间的通讯。 由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用, RPC 的协议有很多,比如最早的 CORBA,Java RMI,Web Service 的 RPC 风格,Hessian,Thrift,甚至 Rest API。
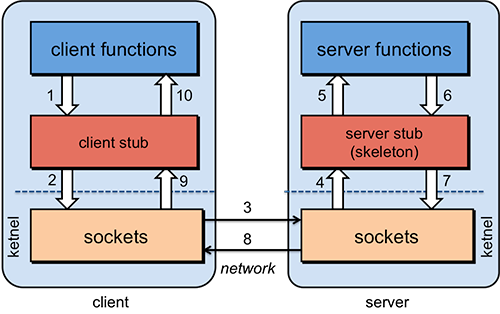
上面是用比较通俗的语言解释了 RPC 相关概念。
这里的一篇远程过程调用(RPC)详解写的非常详细,需要看看。
Ref
远程过程调用(RPC)详解
谁能用通俗的语言解释一下什么是 RPC 框架?
“斗鱼直播平台后端 RPC 架构浅析”
